8. Network analysis
Learning goals
By the end of this tutorial, you will be able to:
- Understand the difference between semantic networks and social networks.
- Build a semantic network from bigrams in text data.
- Build a social network from user mentions and replies.
- Interpret common network measures such as degree, betweenness, and community structure.
- Visualize networks using igraph and ggraph.
Introduction to Network Analysis
Network analysis helps us study relationships rather than isolated observations. In text analysis, this can mean examining how words co-occur with one another. In social media research, it can mean examining how users interact through replies and mentions.
In this tutorial, we cover two related applications:
- Semantic network analysis, which maps connections among words
- Social network analysis, which maps connections among users
A network has two basic parts:
- nodes, which represent words or users
- edges, which represent relationships between them
Required Packages
You only need to install packages once.
Importing data
For this tutorial, we use a CSV file containing abortion-related Twitter data.
tweets <- read.csv("~/Desktop/abortion_tweets.csv", header = TRUE, sep = ",")
tweets_subset <- tweets %>%
select(
id,
author_id,
created_at,
text,
public_metrics.impression_count,
public_metrics.like_count,
public_metrics.quote_count,
public_metrics.reply_count,
public_metrics.retweet_count,
referenced_tweets,
in_reply_to_user_id,
entities.mentions
)
head(tweets_subset) id author_id created_at
1 1608879536376262656 1293292839963631616 2022-12-30T17:35:47.000Z
2 1608879534690160640 1407429095005245440 2022-12-30T17:35:47.000Z
3 1608879520039448320 925802396609073280 2022-12-30T17:35:43.000Z
4 1608879519641002240 99833187 2022-12-30T17:35:43.000Z
5 1608879518382718720 228617818 2022-12-30T17:35:43.000Z
6 1608879503165780224 3206943202 2022-12-30T17:35:39.000Z
text
1 RT @KelseyDotOrg: Today my piece for @atrupar’s Public Notice on abortion access in Missouri and Kansas is up. Thank you Aaron for the oppo…
2 You know any of these hags? Get Paid! $10,000 Reward for Info https://t.co/mgpx6PoQTo via @gatewaypundit
3 RT @mjs_DC: After being denied basic miscarriage care during two separate visits to the ER because of Louisiana's abortion ban, Kaitlyn Jos…
4 RT @MrAndyNgo: Jennifer Thompson, an extremist abortion & BLM activist in Portland, has shared in graphic detail her recent decision to end…
5 RT @LifeNewsToo: The FBI has arrested a dozen pro-life Americans for peacefully protesting abortion, but not one single leftist for firebom…
6 RT @Moneymykpt2: Them Weeks Fly when you tryna get that Abortion 😭
public_metrics.impression_count public_metrics.like_count
1 0 0
2 10 1
3 0 0
4 0 0
5 0 0
6 0 0
public_metrics.quote_count public_metrics.reply_count
1 0 0
2 0 0
3 0 0
4 0 0
5 0 0
6 0 0
public_metrics.retweet_count referenced_tweets
1 190 retweeted, 1608817588376834048
2 1
3 1027 retweeted, 1608871631765786624
4 2278 retweeted, 1529674574266257408
5 41 retweeted, 1608860717515423744
6 367 retweeted, 1603919700890640389
in_reply_to_user_id
1 NA
2 NA
3 NA
4 NA
5 NA
6 NA
entities.mentions
1 c(3, 37), c(16, 45), c("KelseyDotOrg", "atrupar"), c("1375165814", "288277167")
2 91, 105, gatewaypundit, 19211550
3 3, 10, mjs_DC, 88215673
4 3, 13, MrAndyNgo, 2835451658
5 3, 15, LifeNewsToo, 74552263
6 3, 15, Moneymykpt2, 1153357658268819457Part 1: Semantic Network Analysis
What is a semantic network?
A semantic network shows how words are connected based on their co-occurrence in text. Here, we use bigrams (two-word combinations) to identify words that frequently appear together.
Step 1: Clean retweet prefixes
We begin by removing leading RT @username patterns so they do not dominate the network.
Step 2: Extract bigrams and remove stopwords
tw_bigram <- tweets_cleaned %>%
unnest_tokens(bigram, text, token = "ngrams", n = 2) %>%
separate(bigram, into = c("word1", "word2"), sep = " ") %>%
filter(
!word1 %in% stop_words$word,
!word2 %in% stop_words$word
) %>%
unite(bigram, word1, word2, sep = " ") %>%
count(bigram, sort = TRUE)
head(tw_bigram) bigram n
1 https t.co 2491
2 12 weeks 677
3 pro life 495
4 anti abortion 386
5 abortion rights 286
6 abortion ban 270Step 3: Separate bigrams into two words
Step 4: Filter infrequent bigrams
The threshold used here (n > 100) is just an example. Lower thresholds keep more word pairs but can make the network harder to read.
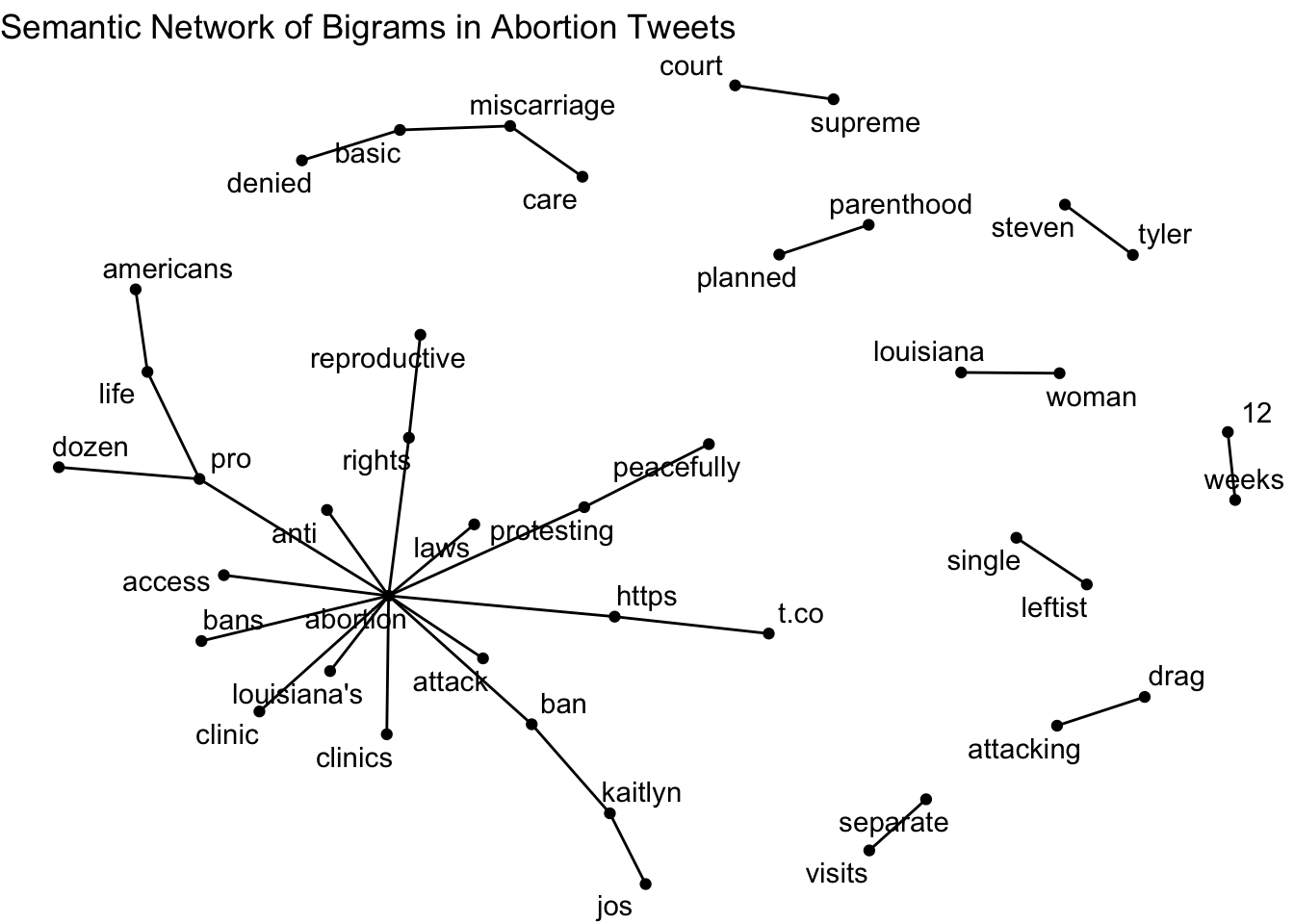
Step 5: Build the network object
Step 6: Visualize the semantic network
Optional: Add directional edges
direction_edges <- grid::arrow(type = "closed", length = unit(.2, "cm"))
ggraph(bigram_graph, layout = "fr") +
geom_edge_link(aes(edge_alpha = n), arrow = direction_edges) +
geom_node_point(size = 2) +
geom_node_text(aes(label = name), repel = TRUE) +
labs(title = "Semantic Network of Bigrams with Directional Information") +
theme_void()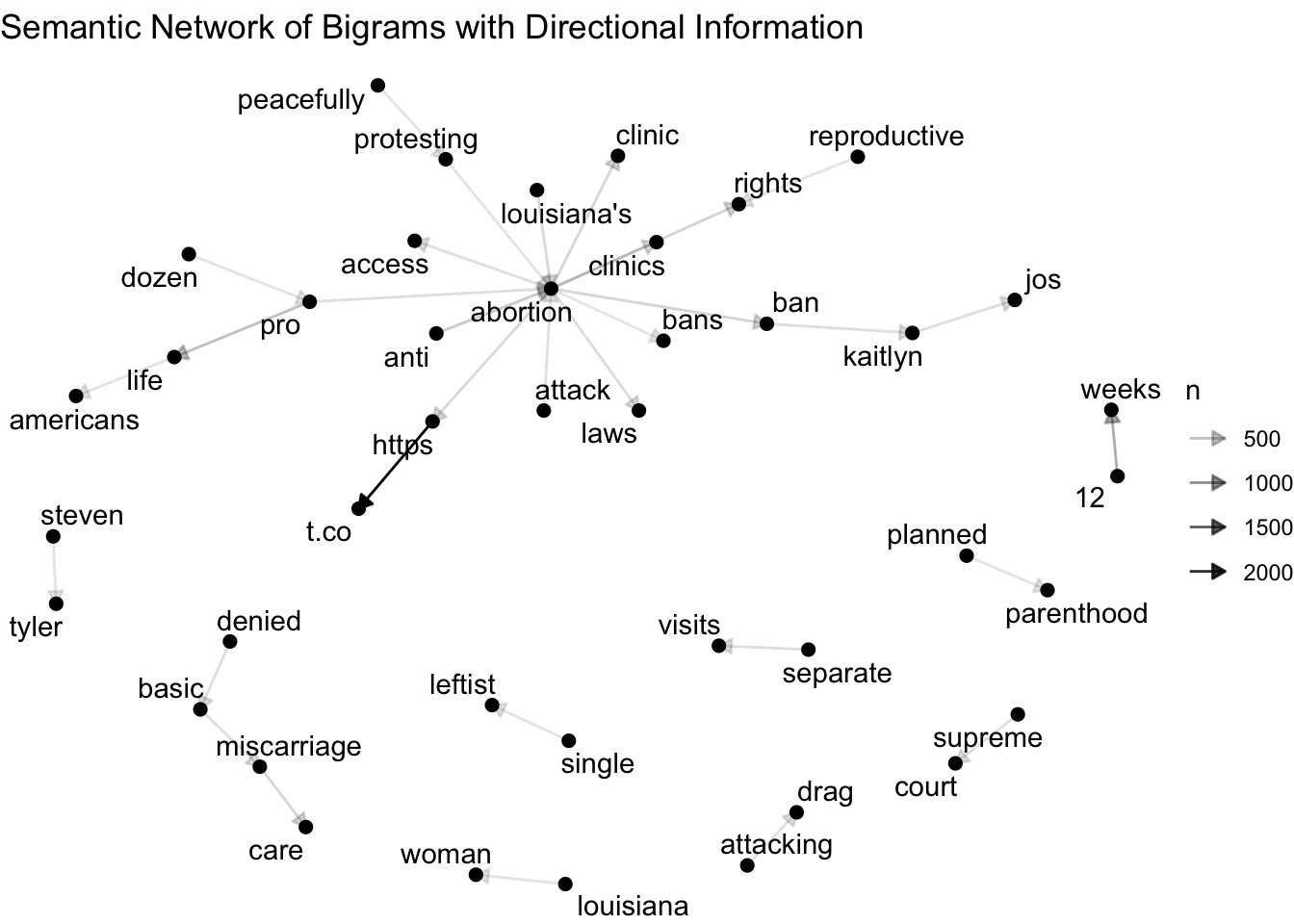
Describe the semantic network
Questions for interpretation
- Which words appear most connected?
- Are there clusters of words representing different themes?
- Do certain words act as bridges between themes?
- What does this suggest about how abortion is discussed in the dataset?
Part 2: Social Network Analysis
In social network analysis, users are the nodes and interactions among users are the edges.
Step 1: Prepare interaction data
Step 2: Build reply and mention edge lists
replies <- tweets_interaction %>%
filter(!is.na(in_reply_to_user_id)) %>%
transmute(
source = as.character(author_id),
target = as.character(in_reply_to_user_id)
)
mentions <- tweets_interaction %>%
mutate(
entities.mentions = as.character(entities.mentions),
mention_ids = str_extract_all(entities.mentions, "(?<!\\d)\\d{4,}(?!\\d)")
) %>%
select(source = author_id, mention_ids) %>%
unnest(mention_ids) %>%
filter(!is.na(mention_ids), mention_ids != "") %>%
transmute(
source = as.character(source),
target = as.character(mention_ids)
)
edges <- bind_rows(replies, mentions) %>%
filter(!is.na(source), !is.na(target), source != "", target != "") %>%
distinct()
head(edges) source target
1 2720585148 1467931973616386048
2 1855645256 1452587928
3 1304024197203550208 1602045892248453120
4 196802928 1428048511547973632
5 171363852 83716493
6 1540777089095401728 1240756589495308288Step 3: Filter to highly connected users
# A tibble: 10 × 2
user n
<chr> <int>
1 88215673 797
2 1467931973616386052 556
3 50434933 320
4 4099171 168
5 1541493458543775747 162
6 288277167 134
7 137472360 97
8 1014756915094515713 95
9 1375165814 89
10 1574645533054046209 84# A tibble: 30 × 2
user n
<chr> <int>
1 88215673 797
2 1467931973616386052 556
3 50434933 320
4 4099171 168
5 1541493458543775747 162
6 288277167 134
7 137472360 97
8 1014756915094515713 95
9 1375165814 89
10 1574645533054046209 84
# ℹ 20 more rowsIn this dataset, a very high threshold can leave too few users to visualize. Here we keep the top 30 most connected users so the network remains readable but still shows more structure.
Step 4: Build and visualize the user network
filtered_edges <- edges %>%
filter(source %in% popular_users$user, target %in% popular_users$user) %>%
count(source, target, sort = TRUE, name = "weight")
user_graph <- graph_from_data_frame(filtered_edges, directed = TRUE)
V(user_graph)$degree_total <- degree(user_graph, mode = "all")
V(user_graph)$degree_in <- degree(user_graph, mode = "in")
V(user_graph)$degree_out <- degree(user_graph, mode = "out")
interaction_graph <- ggraph(user_graph, layout = "fr") +
geom_edge_link(
aes(width = weight, alpha = weight),
arrow = arrow(type = "closed", length = unit(0.12, "cm")),
end_cap = circle(2.5, "mm")
) +
geom_node_point(aes(size = degree_total), color = "steelblue4") +
geom_node_text(aes(label = name), repel = TRUE, size = 3) +
scale_edge_width(range = c(0.2, 1.5)) +
scale_edge_alpha(range = c(0.2, 0.7)) +
scale_size(range = c(2, 8)) +
labs(title = "Twitter User Interaction Network") +
theme_void()
interaction_graph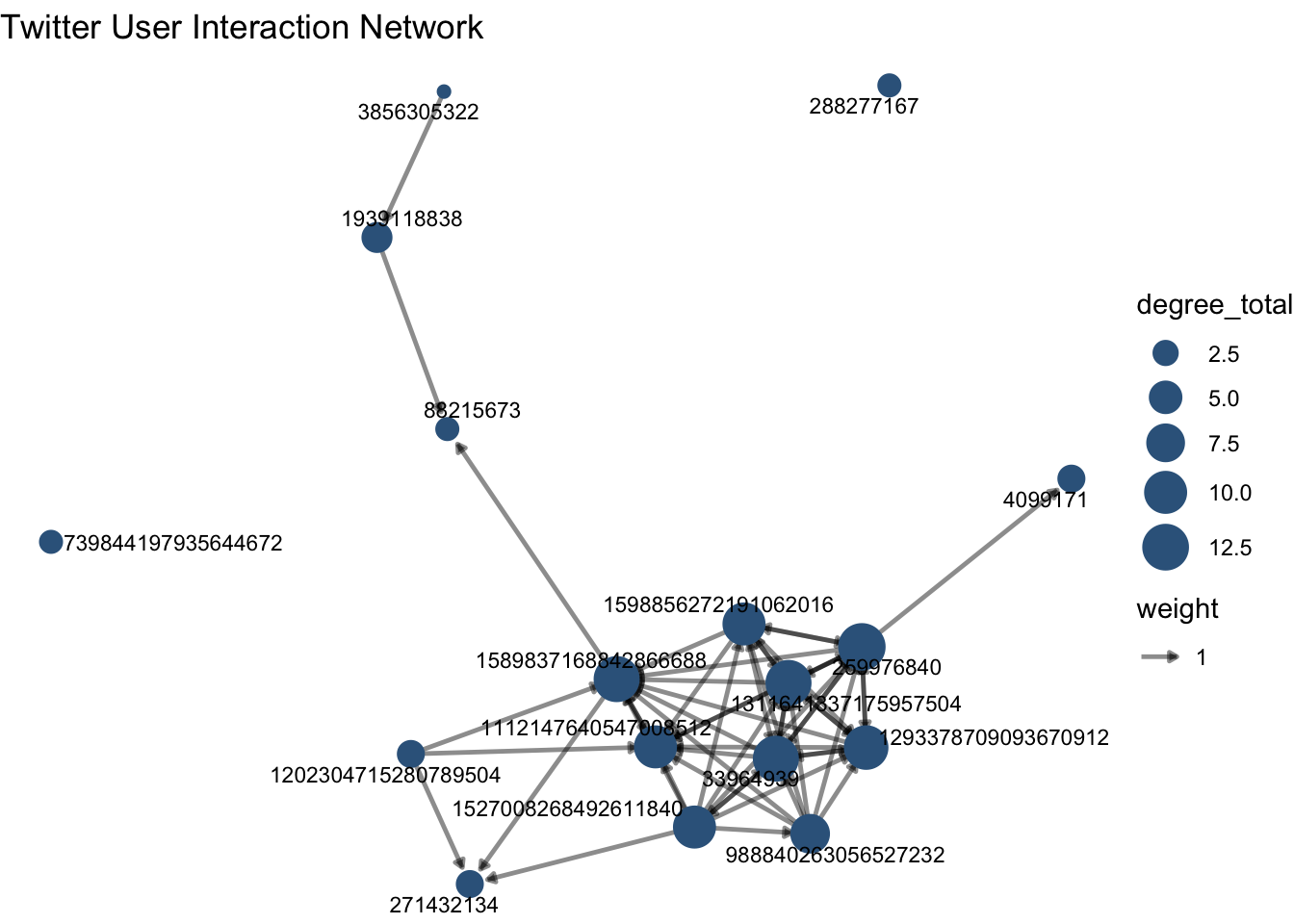
Interpret user interactions
In this graph:
- nodes represent Twitter users
- edges represent mentions or replies
- more connected nodes indicate users with more ties to others in the network
If you want to inspect a specific user ID, you can sometimes search the platform directly using a format like from:USER_ID, as long as the account is still public and available.
Step 5: Degree and betweenness centrality
centrality_table <- tibble(
user = names(degree(user_graph, mode = "all")),
degree_total = as.numeric(degree(user_graph, mode = "all")),
degree_in = as.numeric(degree(user_graph, mode = "in")),
degree_out = as.numeric(degree(user_graph, mode = "out")),
betweenness = as.numeric(betweenness(user_graph, directed = TRUE))
)
centrality_table %>%
arrange(desc(degree_total)) %>%
slice_head(n = 10)# A tibble: 10 × 5
user degree_total degree_in degree_out betweenness
<chr> <dbl> <dbl> <dbl> <dbl>
1 259976840 13 6 7 6.83
2 1311641337175957504 12 6 6 0.833
3 1589837168842866688 12 9 3 15.5
4 33964939 12 6 6 9
5 1293378709093670912 11 6 5 0
6 1112147640547008512 10 9 1 0
7 1527008268492611840 10 1 9 5.83
8 1598856272191062016 10 4 6 0
9 988840263056527232 8 1 7 0
10 1939118838 4 2 2 1 # A tibble: 10 × 5
user degree_total degree_in degree_out betweenness
<chr> <dbl> <dbl> <dbl> <dbl>
1 1589837168842866688 12 9 3 15.5
2 33964939 12 6 6 9
3 259976840 13 6 7 6.83
4 1527008268492611840 10 1 9 5.83
5 1939118838 4 2 2 1
6 1311641337175957504 12 6 6 0.833
7 1112147640547008512 10 9 1 0
8 1202304715280789504 3 0 3 0
9 1293378709093670912 11 6 5 0
10 1598856272191062016 10 4 6 0 Extra: Basic network description
[1] 17[1] 59[1] 0.2169118[1] 3How to interpret these numbers
- More nodes means more unique users are involved.
- More edges means more interactions are taking place.
- Higher density means users are more interconnected.
- More components means the network contains separate groups that are not connected to each other.
Extra: Compare in-degree and out-degree
# A tibble: 10 × 3
user degree_in degree_out
<chr> <dbl> <dbl>
1 1589837168842866688 9 3
2 1112147640547008512 9 1
3 259976840 6 7
4 1311641337175957504 6 6
5 33964939 6 6
6 1293378709093670912 6 5
7 1598856272191062016 4 6
8 271432134 3 0
9 1939118838 2 2
10 4099171 2 1# A tibble: 10 × 3
user degree_in degree_out
<chr> <dbl> <dbl>
1 1527008268492611840 1 9
2 259976840 6 7
3 988840263056527232 1 7
4 1311641337175957504 6 6
5 33964939 6 6
6 1598856272191062016 4 6
7 1293378709093670912 6 5
8 1589837168842866688 9 3
9 1202304715280789504 0 3
10 1939118838 2 2How to interpret this
- High in-degree users are frequently mentioned or replied to.
- High out-degree users are highly active in reaching out to others.
- These are not always the same users.
Extra: Detect communities in the network
Extra: Visualize communities
community_graph <- as_tbl_graph(user_graph_undirected) %>%
activate(nodes) %>%
mutate(community = as.factor(membership(comm)))
community_plot <- ggraph(community_graph, layout = "fr") +
geom_edge_link(alpha = 0.15) +
geom_node_point(aes(color = community), size = 3) +
labs(title = "Communities in the Twitter Interaction Network") +
theme_void()
print(community_plot)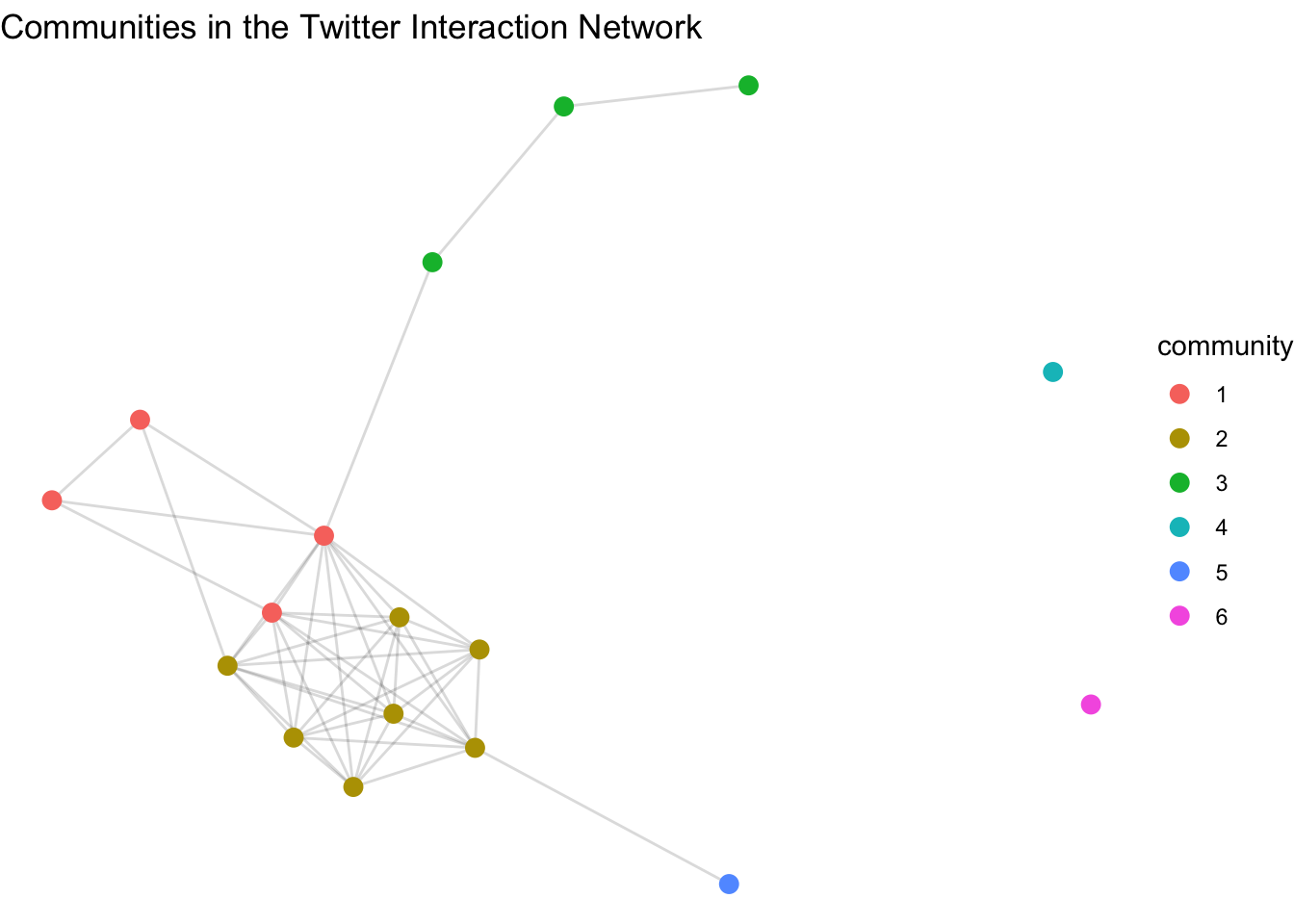
Summary
In this tutorial, you learned how to:
- construct a semantic network from bigrams
- visualize relationships among words using
igraphandggraph - construct a social network from user mentions and replies
- interpret common network measures such as degree, betweenness, density, and modularity
Network analysis is useful because it helps us move from isolated units of text or users to the broader relational structure that shapes communication.